Overview
DeepCausality follows a first principal architecture combined with a handful implementation principles to achieve a high degree of functionality with efficient and straightforward implementation. DeepCausality’s architecture uses the four layers of causal reasoning to achieve these goals.
Four layers of causal reasoning
Conceptually, causal reasoning relies on four pillars: observations, assumptions, inferences, and causes, as depicted in the diagram below.

Observations
The data we observe in the world around us are observations; by themselves, observations do not convey any meaning. Instead, observations are considered to be raw data that require a frame of reference to give meaningful information. Unfortunately, the field of computational causality does not have a conceptualization of a frame of reference. Therefore, an observation is only interpreted in relation to its assumptions.
Assumptions
Causal reasoning does rely on assumptions, but unlike deep learning, best practice dictates that those assumptions are explicit and testable.
Inference
Inference refers to deriving insights from an observation under the stated assumptions. The expressiveness of inference depends to a large extent on the stated assumptions because observations are just raw data. As strict as the definition of inference sounds, it is already potent in practice because it allows significant estimates:
- How many observations are inferable?
- How many observations are inverse inferable?
- How many observations are non-inferable?
- What is the ratio between inferable and non-inferable observations?
- What is the ratio between inferable and inverse-inferable observations?
Causality
A causal relation between a cause A and an effect E is defined as
IF (cause) A then (effect) E
AND
IF NOT (cause) A, then NOT (effect) E
Both criteria must be true for a causal relation. Therefore, previous estimates from inference help to search for causal relations, in particular:
For a known effect E, it is believed that observation A in the data might be a likely cause. Another observation B might be a possible cause, but it is believed to be less likely. With the inference mechanism, the pattern of A and B can be expressed with the idea that if observation A and effect E occur, it counts as an inference. If no A occurs and E does not, it counts as an inverse inference.
In the case that there is roughly an equal number of inferences, and inverse inference, a clear-cut causal relation has been found. In practice, imbalance between inferences and inverse-inferences happen for many reasons including data sampling. If there is just a correlation between observation A and effect E, then the imbalance is too extreme and cannot be reconciled, even with increased data sampling. Also, a large percentage of non-inferable data indicates correlation.
Once the causal relation has been established, it governs all subsequent inferences for as long as the causal relation holds. Judging by experience, many causal mechanisms tend to remain stable unless some structural change occurs. Also, the feasibility of a transfer of causal relations to a new dataset can be tested via the underlying assumptions. As long as the assumptions are fully testable, the process of transferring causal relations and even causal models can be automated.
Core Architecture
The core architecture of DeepCausality, excluding context, has translated each of the four layers of causal reasoning into a trait with a matching type.
- Observable | Observation
- Assumable | Assumption
- Inferable | Inference
- Causable | Causaloid
Also, each layer has been translated into a reasoning trait that provides a default implementation for reasoning over a collection of items.
- Observable reasoning
- Assumable reasoning
- Inferable reasoning
- Causable reasoning
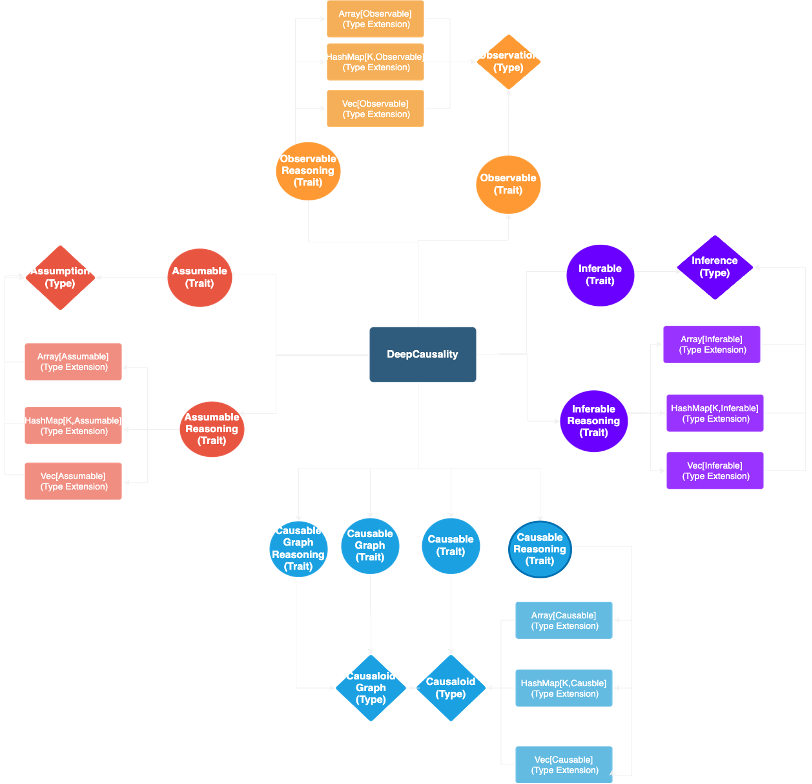
Because Rust does not have unified collections, the default implementation of a reasoning type needs to be mixed into each applicable collection using the type extension pattern. DeepCausality provides type extension for all reasoning traits for the following collections:
- Array
- HashMap
- BTreeMap (new)
- Vector
- VecDeque (new)
HashSet and BTreeSet have been excluded because sets in Rust only store keys without values, which is unsuitable for storing a collection of items. That said, the type extension can be applied to custom collection types if the requirements specified in the reasoning trait are met.
The causal reasoning requires four traits because the hyper-graph implementation is separate from the collection type extension and thus requires two more traits. This design is very similar to the architecture of the context.
Context architecture
To the left side of the diagram, we have the contextuable and the contextuable graph trait which is implemented in the matching type. The contextoid only depends on the defining trait, thus leaving the option to define custom types to store in the context. The context graph abstracts over multiple categories of node types defined as traits and types:
- Datable | Data
- Spatial | Space
- SpaceTemporal | SpaceTime
- Temporal | Time
The underlying idea is that each unit of context, called a contextoid, stores a unit of data, time, space, or spacetime.
It is important to know that all these node types are immutable by default and can only be used in an immutable context. The mutable counterparts all implement the adjustable protocol:
- Datable + Adjustable | AdjustableData
- Spatial + Adjustable | AdjustableSpace
- SpaceTemporal + Adjustable | AdjustableSpaceTime
- Temporal + Adjustable | AdjustableTime
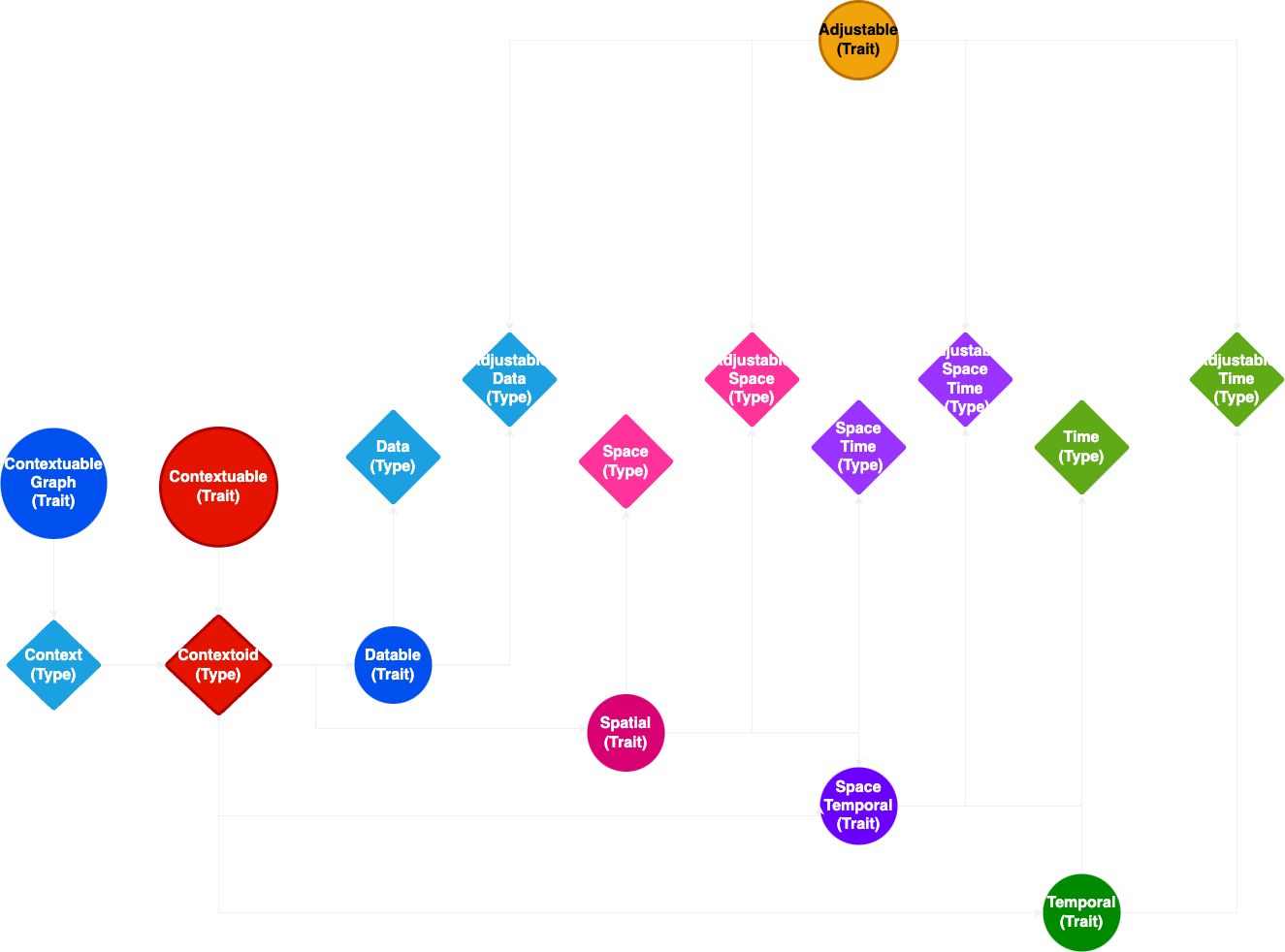
The contextoid does not depend on the adjustable trait, and a context may freely mix immutable and mutable node types. Furthermore, DeepCausality does not provide a global update mechanism with the understanding that the details of a node update are subject to the actual implementation,
Implementation principles
The implementation of the architecture relies on three core concepts:
- Protocol bases reasoning
- Recursive isomorphic data structures (self-referential types in Rust)
- Disjoint algebraic types (Nested Enums in Rust)
Protocol-based reasoning remains the central pillar of DeepCausality as it enables an efficient yet easy-to-maintain implementation. Specifically, as outlined in the architecture diagrams, each domain is represented by a few traits. All business logic resides only in the default implementation of the reasoning traits. The advantage of a default implementation is providing a single source of truth and a single source of maintenance while still having the flexibility of, at least partially, overwriting the default implementation.
To illustrate the power of this approach, the causal reasoning trait and its default implementation account for about 110 LoC and require four methods to be present in the implementing type. The type extension for each of the five supported collections is implemented with compiler macros that generate the four methods required by the trait. Each type extension is about ten lines, meaning all five require less code than the actual default implementation while leaving the core logic in one place. A potential bugfix applied to the default implementation propagates to all five type extensions, thus significantly simplifying maintenance.
Next: Background
About
DeepCausality is a hyper-geometric computational causality library that enables fast and deterministic context-aware causal reasoning in Rust. Please give us a star on GitHub.